# CAPTCHA Images
# Цель
Проанализировать насколько эффективны текстовые капчи распознавая их с помощью машинного обучения
# Задачи
- [ ] Анализ существующих решений.
- [ ] Сбор данных и их обновление.
- [ ] Обучение и оценка моделей на исходном датасете.
- [ ] Выбор двух моделей с наибольшим значением точности.
- [ ] Оценка качества и скорости работы модели на новых CAPTCHA путем A / B тестирования.
- [ ] Выбор и развертывание наилучшей модели.
- [ ] Оптимизация выбранной модели путем квантизации и дистилляции.
- [ ] Развертывание оптимизированной модели, количественная оценка эффекта оптимизации.
# Датасет
# Целесообразность
Этот набор данных содержит изображения CAPTCHA (полностью автоматизированный общедоступный тест Тьюринга, позволяющий различать компьютеры и людей). Создан в 1997 году, чтобы пользователи могли идентифицировать и блокировать ботов (для предотвращения спама, DDOS и т. д.).
Содержание
Изображения представляют собой слова из 5 букв, которые могут содержать цифры. К изображениям был применен шум (размытие и линия). Они имеют размер 200 на 50.
Обзор датасета (opens new window)
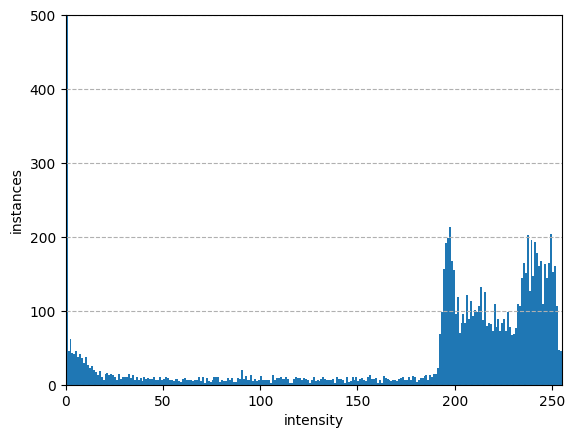
Можно посмотреть на пример гистограммы интенсивности. Обратите внимание
разрыв между интенсивностью около 0 (передний план) и
255 (фон)
Если взглянуть на символы на изображениях CAPTCHA, можно заметить, что:
- используются только 19 символов 2,3,4,5,6,7,8 и b,c,d,e,f,g,m,n,p,w,x,y
- частота каждого символа примерно одинакова, за одним исключением: n используется в два раза чаще, чем другие символы.

Проект: CAPTCHA (opens new window)
Эти данные можно применить для машинного обучения нейросети распознование симвлов
# Диаграммы
- Component diagram;
- Activity diagram;
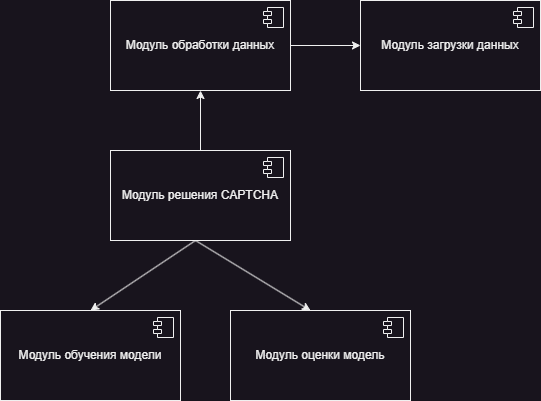
# Component diagram
# Activity diagram